How-To: Operationalizing GIS Spatial Analytics for Predictive Maintenance in Municipal Water Grids

Discover how water infrastructure managers can operationalize GIS spatial analytics and SCADA telemetry to drive predictive maintenance in municipal water grids. This technical case study provides actionable Python workflows, spatial data architectures, and machine learning strategies to reduce non-revenue water (NRW) and prevent catastrophic infrastructure failures.
- The Paradigm Shift: From Reactive Repairs to Spatial Predictive Maintenance
- Architecting the SCADA-GIS Data Pipeline
- Data Fusion: Merging Spatial Topologies with Telemetry
- Predictive Modeling: Python Implementation for Risk Scoring
- Comparative Analysis of Maintenance Strategies
- Scaling the Architecture: Edge Analytics and Heavy Asset Integration
- Conclusion
The Paradigm Shift: From Reactive Repairs to Spatial Predictive Maintenance
For decades, municipal water grids have operated on a break-fix paradigm. water infrastructure managers relied on reactive maintenance, dispatching crews only after a main break caused significant surface flooding or a severe drop in system pressure. This approach results in exorbitant emergency repair costs, massive volumes of Non-Revenue water (NRW), and accelerated degradation of adjacent infrastructure. As a Senior SCADA Architect, I advocate for a strict, data-driven methodology: operationalizing Geographic Information Systems (GIS) spatial analytics in tandem with high-resolution SCADA telemetry to predict and preempt failures before they occur.
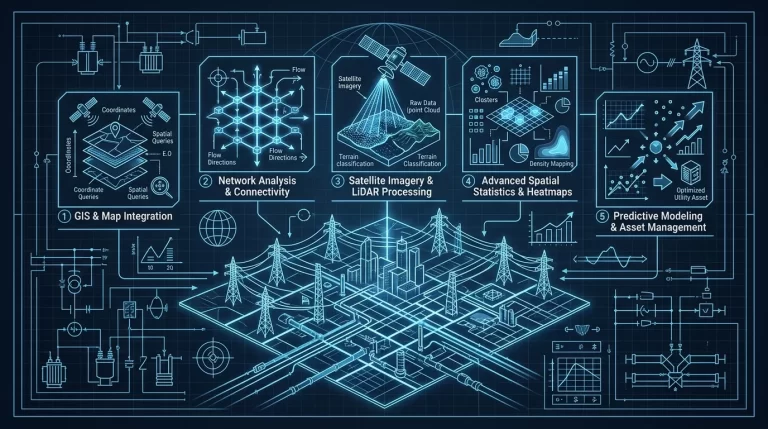
Predictive maintenance in water grids is inherently a spatial problem. A pipe’s probability of failure is not merely a function of its age or material; it is heavily influenced by spatial variables such as soil corrosivity, elevation changes, proximity to heavy traffic loads, and hydraulic pressure transients recorded by localized SCADA RTUs (Remote Terminal Units). By fusing time-series SCADA data with static GIS topologies, utilities can generate dynamic risk matrices that dictate targeted, highly efficient maintenance schedules.
Architecting the SCADA-GIS Data Pipeline
To operationalize this strategy, utilities must first dismantle the silos between their Operational Technology (OT) networks and their enterprise GIS databases. SCADA systems excel at capturing high-frequency time-series data (e.g., flow rates, pressure spikes, pump statuses via DNP3 or Modbus TCP), while GIS platforms manage complex spatial relationships and asset metadata.
The architectural foundation requires an automated ETL (Extract, Transform, Load) pipeline that normalizes SCADA telemetry and maps it to specific spatial coordinates. This involves establishing a unified Coordinate Reference System (CRS) and ensuring that every SCADA tag is strictly associated with a GIS Asset ID. While the focus here is on water grids, the underlying principles of spatial data normalization are highly analogous to advanced QGIS spatial data integration and topology mapping for utility-scale power grids, where precise topological relationships dictate grid resilience and load balancing.
Data Fusion: Merging Spatial Topologies with Telemetry
The core of the analytics engine relies on spatial joins. When a pressure transient (water hammer) is detected by a SCADA pressure sensor, the analytics engine must propagate that stress factor along the GIS pipe network, accounting for friction loss and elevation. Pipes situated in highly corrosive soil (identified via GIS polygons) that frequently experience high-pressure anomalies (identified via SCADA time-series data) are flagged with the highest risk coefficients.
Predictive Modeling: Python Implementation for Risk Scoring
To move from theoretical architecture to practical application, we utilize Python to build a machine learning model that calculates failure probabilities. The following code block demonstrates how to fuse GeoJSON spatial data with historical SCADA telemetry using GeoPandas, and how to train a Random Forest classifier to identify high-risk pipe segments.
import geopandas as gpd
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import numpy as np
# 1. Load GIS pipe network data (Spatial Asset Metadata)
pipes_gdf = gpd.read_file('gis_water_mains.geojson')
# 2. Load SCADA historical pressure anomaly data (Aggregated Time-Series)
scada_df = pd.read_csv('scada_pressure_transients.csv')
# 3. Data Fusion: Merge spatial data with SCADA telemetry based on Asset_ID
fusion_df = pipes_gdf.merge(scada_df, on='Asset_ID', how='left')
# 4. Feature Engineering: Calculate age, encode material, handle missing telemetry
fusion_df['Pipe_Age'] = 2024 - fusion_df['Install_Year']
fusion_df['Material_Code'] = fusion_df['Material'].astype('category').cat.codes
# Define critical features for the predictive model
features = [
'Pipe_Age',
'Material_Code',
'Soil_Corrosivity_Index',
'Max_Pressure_Spike_PSI',
'Avg_Flow_Velocity'
]
# Prepare feature matrix (X) and target vector (y)
X = fusion_df[features].fillna(0) # Impute missing SCADA data with 0 for baseline
y = fusion_df['Historical_Failure_Flag']
# 5. Initialize and train the Random Forest model
# Hyperparameters tuned for spatial-temporal utility data
rf_model = RandomForestClassifier(n_estimators=150, random_state=42, max_depth=12)
rf_model.fit(X, y)
# 6. Predict failure probability for the next 12-month operational cycle
fusion_df['Failure_Probability'] = rf_model.predict_proba(X)[:, 1]
# 7. Export high-risk spatial subset for GIS maintenance routing
high_risk_pipes = fusion_df[fusion_df['Failure_Probability'] > 0.80]
high_risk_pipes.to_file('predictive_maintenance_routes.geojson', driver='GeoJSON')
print(f"CRITICAL ALERT: Identified {len(high_risk_pipes)} high-risk pipe segments requiring immediate acoustic leak detection.")
This script operationalizes the data by outputting a new GeoJSON layer containing only the assets with an 80% or higher probability of failure. water infrastructure managers can ingest this layer directly into their enterprise GIS viewers, allowing field crews to prioritize acoustic leak detection and non-destructive testing on these exact coordinates.
Comparative Analysis of Maintenance Strategies
To justify the capital expenditure (CapEx) required to build this SCADA-GIS integration, infrastructure managers must understand the stark operational differences between legacy strategies and spatial predictive maintenance. The table below outlines the comparative metrics:
| Maintenance Strategy | Primary Data Inputs | O&M Cost Impact | NRW Reduction Potential | Implementation Complexity |
|---|---|---|---|---|
| Reactive (Run-to-Failure) | Customer Complaints, Visible Surface Leaks | Highest (Emergency overtime, collateral infrastructure damage) | Minimal to None | Very Low |
| Time-Based (Preventative) | Asset Age, Manufacturer MTBF specs | Moderate (Frequent replacement of healthy assets) | Low to Moderate | Low (Basic CMMS integration) |
| GIS-Spatial Predictive | SCADA Telemetry, Soil Data, Topography, Machine Learning | Lowest (Optimized crew routing, extended asset lifecycles) | Maximum (Preempts bursts before substantial leakage) | High (Requires robust ETL, Python/ML pipelines) |
Scaling the Architecture: Edge Analytics and Heavy Asset Integration
Once the spatial analytics pipeline is operationalized for the static pipe network, the next architectural evolution involves integrating dynamic, heavy mechanical assets such as booster pump stations and pressure reducing valves (PRVs). The failure of a primary pump can introduce massive hydraulic transients into the grid, invalidating baseline spatial risk scores.
To mitigate this, utilities must push analytics closer to the edge. By integrating high-frequency IIoT sensors directly on the pump chassis, SCADA architects can capture micro-anomalies before they manifest as hydraulic shocks. This methodology is heavily reliant on scaling AI-driven vibration analysis for predictive maintenance in SCADA-integrated water infrastructure. When a pump’s vibration signature deviates from its baseline, the edge device alerts the central GIS engine, which then dynamically recalculates the failure probability of all downstream pipe segments based on the anticipated hydraulic instability.
Conclusion
Operationalizing GIS spatial analytics within municipal water grids is no longer an experimental luxury; it is a strict operational necessity for utilities facing aging infrastructure and stringent regulatory targets for NRW reduction. By breaking down the data silos between SCADA telemetry and GIS metadata, and applying rigorous machine learning models via Python, water infrastructure managers can transition from a costly reactive posture to a highly optimized, predictive operational model. The initial complexity of architecting these data pipelines is rapidly offset by the profound reduction in emergency repairs, extended asset lifecycles, and the preservation of critical water resources.